誤差項はモデル式の従属変数に影響を与えるであろう説明変数以外の諸要素を一つの誤差として代表させており、平均値ゼロ、標準偏差1の正規分布に従い、説明変数とは独立していると仮定している。
1年間の販売数量については当該企業の過去の実績から予想して最小値1000、最大値10000、最頻値5000の三角分布をすると仮定した。
このような前提でモデル式を一定の関数に定義して、それを2万回計算するモンテカルロシミュレーションを行うことにした。
シミュレーションはフリーの統計ソフトRを使い簡単なプログラムを作成して実行する。モンテカルロ法では疑似乱数を使うので乱数の品質を心配する人もいるが、Rでは MATLABと同様に メルセンヌ・ツイスター法(Mersenne twister)が使われており乱数の品質でも遜色ないようだ。
ここでのモデルは単純であるが実際にはもっと複雑なモデルが想定される。しかし、モデルを作るとき、多数の変数を使い過度に複雑なモデルにすると実用的でなくなるかもしれない。1970年代に計量経済学の世界で大型のマクロ同時方程式モデルの有効性の議論(註1)が起こったが、これと似たようなことに直面する可能性がある。局所的なモデルで臨機応変に対応する方が時間もコストも節約できて実践的と思われる。
このモデルで2万回の試行を行って得た結果は以下のようなものであった。(分析に使ったRコードは末尾に示してある。)
販売数量の分布
1年間の販売数量は過去の実績から、最小値1000、最大値10000、最頻値5000の三角分布に従うと仮定した。三角分布は最小値と最大値が特定されているので希に発生する極値が反映されないといった弱点はあるが当該企業の経験則から短期的には極値は発生しないだろうと仮定された。モンテカルロ実験では販売数量の分布は以下のようになった。
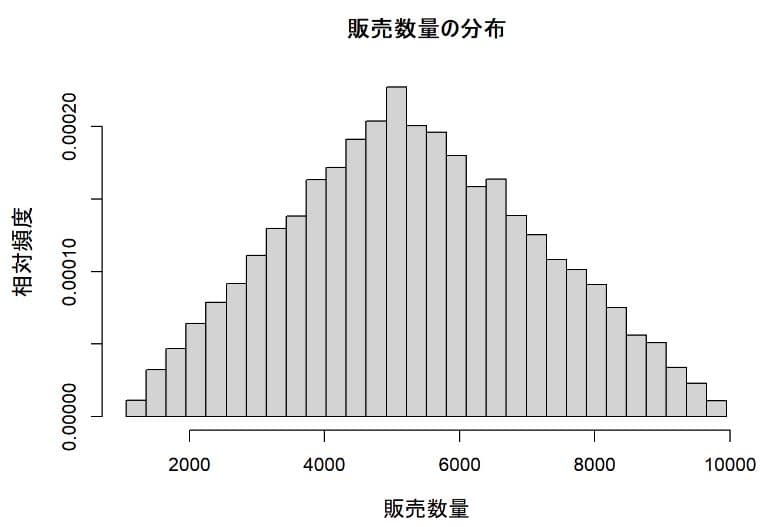
度数分布図を見ると6000個より少し小さい辺りが分布の中心に見える。平均値、標準偏差などの主要な記述統計量を見てみると
平均値が5326.53で歪度(skew)が0.11とゼロに近いのでほぼ左右対称であることが分かる。
販売価格の分布
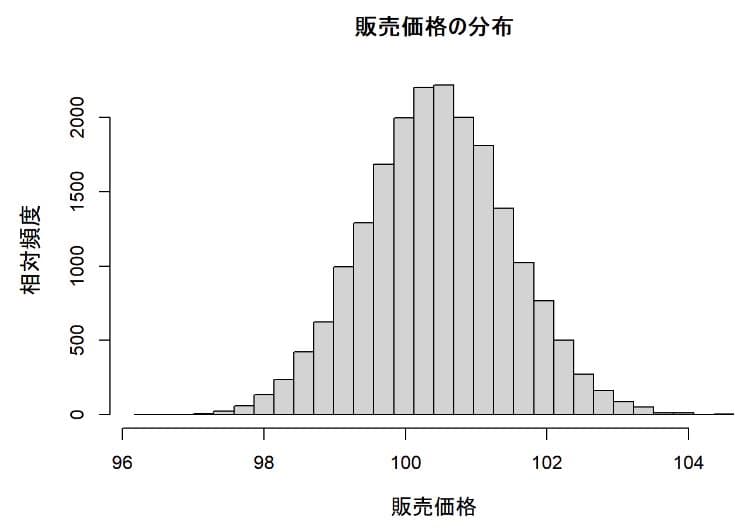
販売単価は100.45円が平均でほぼ左右対称になっている。
単位変動原価の分布
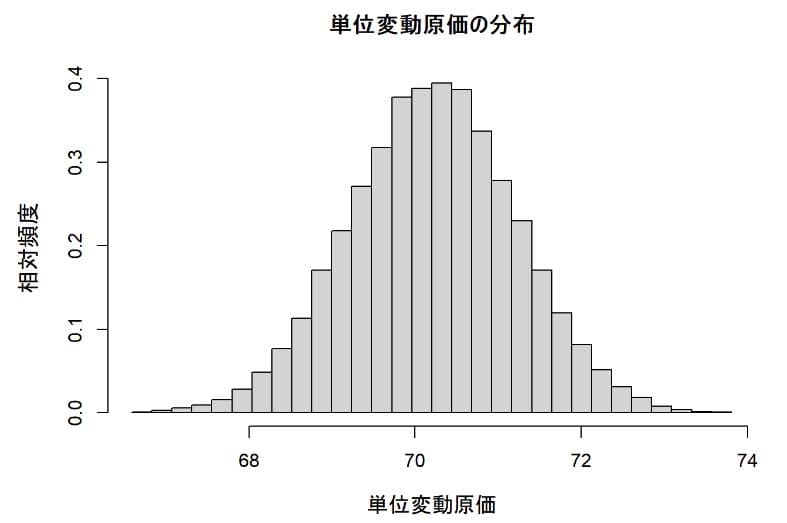
単位変動原価の平均は70.22円が平均値となっている。
限界利益の分布
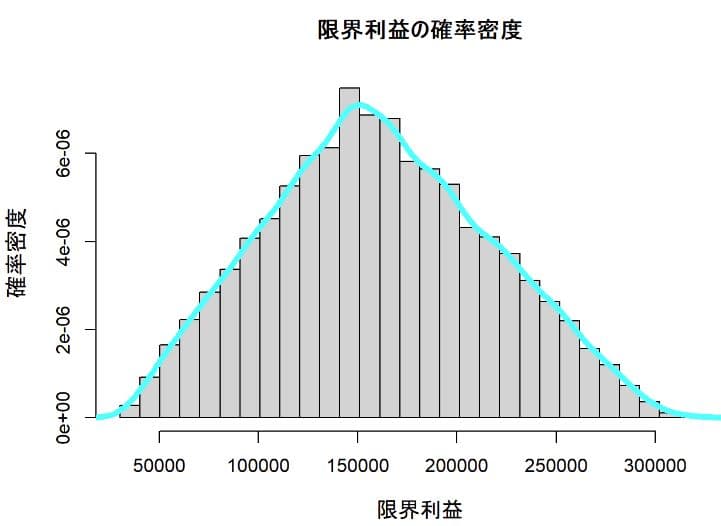
限界利益の確率密度も販売数量の分布から予想されたようにほぼ左右対称で平均値は160855.6円となっている。
確率密度を一定のレンジで、その面積を合計(積分)したものが確率になるが、それを読み取りやすくするために最小値から最大値に向かって累積させたグラフが以下の分布関数グラフとなる。観測値を最小値から最大値に向けて大きさの順に並べた時にその観測データを任意の整数kに等分する順序統計量をk分位数というよんでいる。経験分布を求めるときには順序統計量を利用し.カーネル(kernel)関数を使って推定されるが幸いにも、このような面倒な計算はソフトが行ってくれる。もっと深掘りするにはノン・パラメトリック(non-parametric)統計学の専門書を参照されたい。
限界利益の累積分布
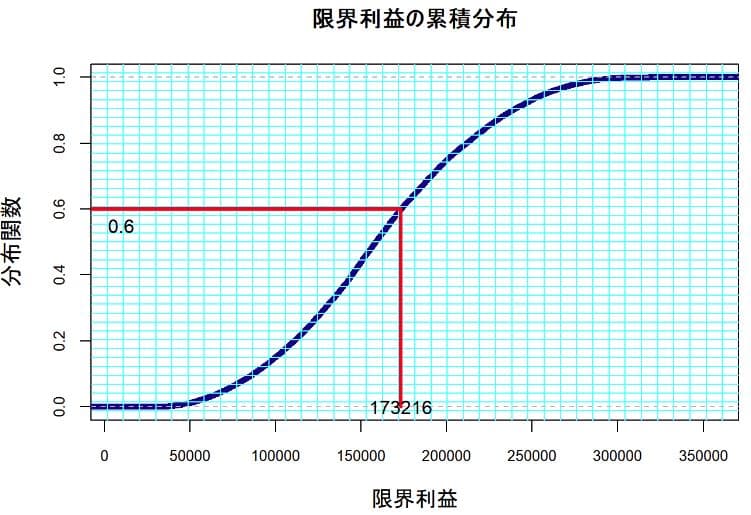
このシミュレーションの結果から見ると、方眼紙風のグラフから限界利益が173216円以下となる確率は0.6つまり60%と読める。言い換えると、173216円以上の限界利益を稼得する確率は40%(=1-0.6)ということが見て取れる。この分布は正規分布といった特定の確率分布を前提としないで、データのヒストグラムから一定の方法で推定された経験分布を表している。平均と分散の2つのパラメータで関数が特定できる正規分布といった特定の確率モデルを想定せずに、シミュレーションの結果による経験分布に基づいて判断するといった大変にチャレンジングな意思決定を試みている。
この分析報告を聞いていた営業部長から最近の消費動向調査によれば消費者の購買意欲は全般的に低下しており、1年くらいは状況は変わらないだろうとの指摘があった。そこで、この指摘を踏まえて販売数量について三角分布の最頻値を5000から3000に変更して第2モデルを作った。第2モデルといっても、三角分布のパラメーターを少し書き換えたにすぎないが、改めてモンテカルロシミュレーションを行ってみた。
第2モデルの前提
販売数量
最小値1000 最大値10000 最頻値3000 の三角分布を仮定
その他の前提条件は変更無し。
販売数量の分布
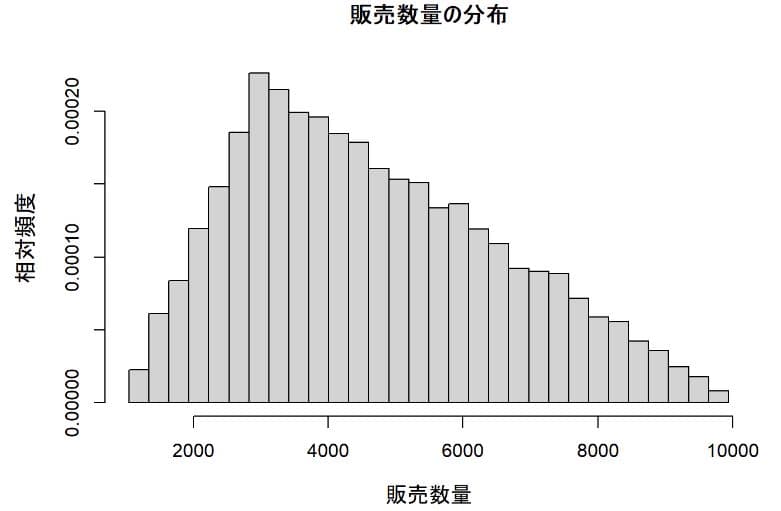
予想通りやや左に偏った度数分布になっている。第1モデルの平均値は5326個であったが、第2モデルでは平均値は4661個と低下している。
販売価格の分布
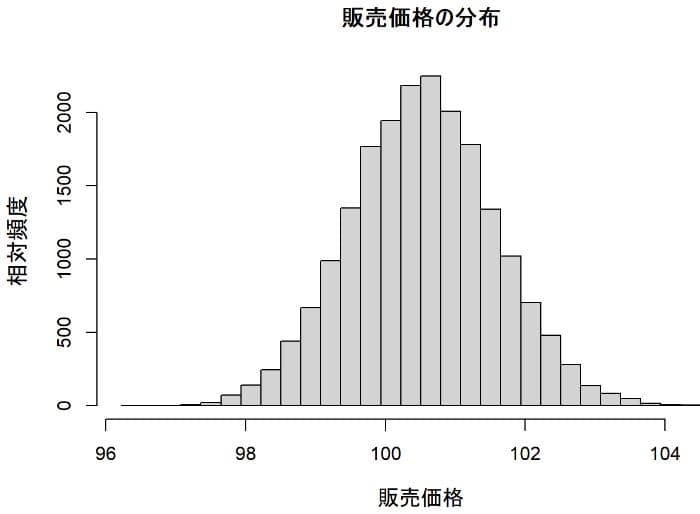
販売単価の分布はモデル式に変更がないので第1モデルとほぼ同じである。販売単価の平均値が100.53円と第1モデルの100.45より増加している。これは価格が販売数量が増えると低下し、販売数量が低下すれば増加するといったトレードオフの関係になっているためである。
単位変動原価の分布
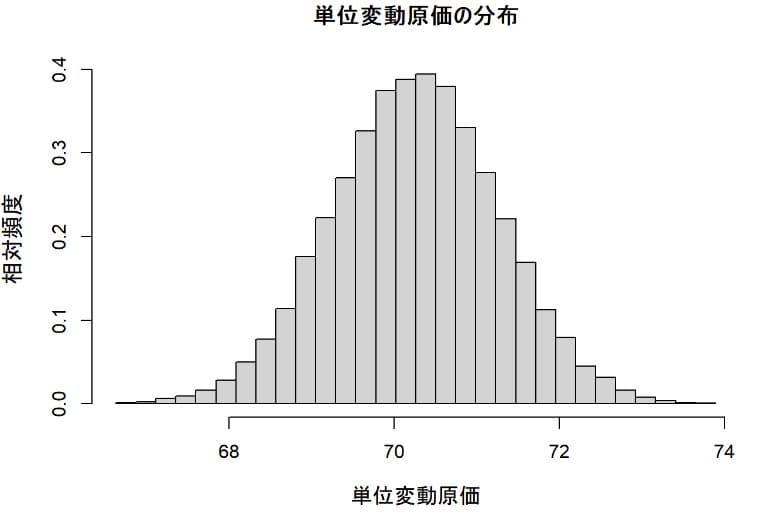
単位変動原価の分布はモデル式に変更がないので第1モデルとほぼ同じである。平均値が70.26円と第1モデルの70.22より増加している。これは変動原価が販売数量が増えると低下し、販売数量が低下すれば増加するといったトレードオフの関係になっているためである。
限界利益の分布
限界利益の確率密度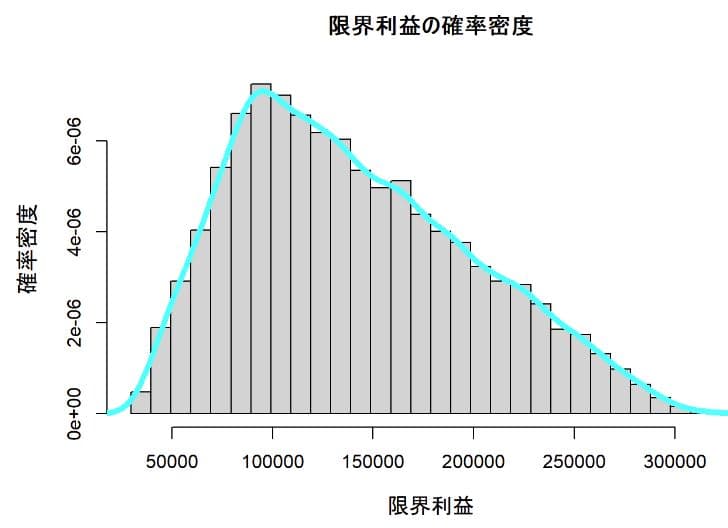
限界利益の確率密度は販売数量の分布から予想されたように左に偏った分布となっている。
限界利益の平均値は140876円で第1モデルの平均値160855円よりも低下している。
限界利益の累積分布
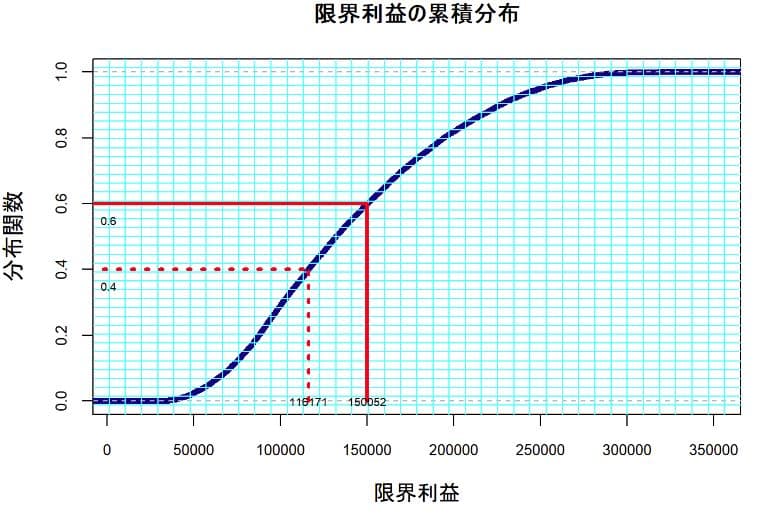
シミュレーションの結果の経験分布グラフから見ると限界利益116171円以下になる確率は40%で150052円以下となる確率は60%と読める。意思決定は人の性格によって異なることもある。60%の確率ならばゴーサインを出す人もいるだろう。このグラフでは限界利益116171円以上を稼得できる確率は60%(=1-0.4)なので、予想される固定費がこの金額を相当程度に下回っていれば計画は採択されるかもしれない。もっと大胆な人がいて40%の確率が見込まれればゴーサインを出すこともあるだろう。このグラフからは150052円以上の限界利益を稼得できる確率は40%(=1-0.6)なので、その金額が要求水準に見合っていれば計画は採択されるかもしれない。世の中には、あまのじゃくな人がいて53%の確率ならゴーサインを出すつもりだが、それはどの程度の限界利益になるのかと問われたならばquantile(x,probs=c(0.47))関数を使うと127282円と計算できる。シミュレーションの結果では127282円以上の限界利益を稼得する確率は53%(=1-0.47)になる。この金額が意思決定者の要求水準に達しているならば計画は採択されるだろう。
自社の特性を反映した適当なモデルが作れればモンテカルロ・シミュレーションでマイ(my)確率分布を探し当て意思決定に使えるかもしれない。何か宝探しをするような期待感がある。
************************
拙文を書くのに使ったRコードは以下の通り。自分の学習用のメモが記入されているが適宜に無視して読まれたい。使用したRは version 4.2.1 でwindows10で作動させた。パッケージのpsychは記述統計量を一括表示するのに便利なので使った。パッケージextraDistr は三角分布のような特殊な確率分布の乱数生成に使った。三角分布なら自作の関数を作る人もいるだろうが、このパッケージはRで標準装備されていない様々な確率分布が用意されているので何かの時に便利と思われる。
library(psych) # 記述統計量の一括出力に使う
library(extraDistr) # 特殊な確率分布の乱数生成に使う
#########################################################
## 販売数量 三角分布の乱数使用
## 販売単価、単位変動原価 誤差項に正規分布の乱数使用
# 販売単価と単位変動費に誤差項を加える
# 反復計算回数が多いのでapply()系の関数で処理する
# 関数の返り値が複数の時はlistを使う。
## 第1モデルの前提
# 販売数量 最小値1000 最大値10000 mode(最頻値)5000
# の三角分布を仮定 最低販売数量1000
# 限界利益=売上高-変動原価
# 売上高=販売単価×販売数量
# 変動原価=単位変動原価×販売数量
# 販売単価=100+2000/販売数量 + 誤差項(正規乱数)
# 単位変動原価=70 + 1000/販売数量 + 誤差項(正規乱数)
# これらの前提にしたがって限界利益を計算する関数を作る
# 限界利益関数(a,b,c は三角分布の引数)
xmtr<-function(a,b,c){
x<-0
sq<- rtriang(1,a,b,c)
sp<- 100+2000/sq + rnorm(1)
cv<- 70+1000/sq + rnorm(1)
x<-sq*sp-cv*sq
return(list(sq,sp,cv,x))}
# 2万回の試行データを得る
set.seed(123)
data1<-replicate(20000,xmtr(1000,10000,5000))
## sapply を 使って replicate と同一の結果を出せる。
set.seed(123)
testdata<-sapply(1:20000,function(i) xmtr(1000,10000,5000))
# data1はリストになっているので、要素毎に数値ベクトルに変換
# 販売数量データ
squant1<-as.numeric(data1[1, ])
sqtest<-as.numeric(testdata[1,])
head((squant1-sqtest),10)
# 販売価格データ
sprice1<-as.numeric(data1[2,])
# 単位変動原価データ
costv1<-as.numeric(data1[3,])
# 限界利益データ
margin1<-as.numeric(data1[4,])
# 販売数量の分布
hist(squant1,prob=T,main="販売数量の分布",
breaks = seq(min(squant1), max(squant1), length.out = 31),
xlab="販売数量",ylab="相対頻度",cex.lab=1.2)
describe(squant1,quant=c(0.2,0.4,0.5,0.6,0.8))
# 販売価格の分布
hist(sprice1,prob=F,main="販売価格の分布",
breaks = seq(min(sprice1), max(sprice1), length.out = 31),
xlab="販売価格",ylab="相対頻度",cex.lab=1.2)
describe(sprice1,quant=c(0.25,0.5,0.75))
# 単位変動原価の分布
hist(costv1,prob=T,main="単位変動原価の分布",
breaks = seq(min(costv1), max(costv1), length.out = 31),
xlab="単位変動原価",ylab="相対頻度",cex.lab=1.2)
describe(costv1,quant=c(0.25,0.5,0.75))
# 限界利益の分布
hist(margin1,freq=F,main="限界利益の確率密度",
breaks = seq(min(margin1), max(margin1), length.out = 31),
xlab="限界利益",ylab="確率密度",cex.lab=1.2)
lines(density(margin1),lwd=5,col="cyan")
describe(margin1,quant=c(0.2,0.4,0.5,0.6,0.8))
plot(ecdf(margin1),col="navy",lwd=5,
xlab="限界利益",ylab="分布関数",cex.axis=0.8,
main="限界利益の累積分布",cex.lab=1.2)
grid(40,40,lwd=1,lty=1,col="cyan")
segments(173216,0,173216,0.6,col="red",lwd=3)
segments(-100000,0.6,173216,0.6,col="red",lwd=3)
text(173216,0,"173216")
text(10000,0.55,"0.6")
qq1<-quantile(margin1,probs=c(0.1,0.2,0.3,0.4,
0.5,0.6,0.7,0.8,0.9))
print(round(qq1,digits=0))
#############################
#############################
#############################
## 第2モデルの前提
# 販売数量 最小値1000 最大値10000 mode(最頻値)3000
# の三角分布を仮定 最低販売数量1000
# 限界利益=売上高-変動原価
# 売上高=販売単価×販売数量
# 変動原価=単位変動原価×販売数量
# 販売単価=100+2000/販売数量 + 誤差項(正規乱数)
# 単位変動原価=70 + 1000/販売数量 + 誤差項(正規乱数)
# これらの前提にしたがって限界利益を計算する関数を作る
# 限界利益関数(a,b,c は三角分布の引数)
xmtr<-function(a,b,c){
x<-0
sq<- rtriang(1,a,b,c)
sp<- 100+2000/sq + rnorm(1)
cv<- 70+1000/sq + rnorm(1)
x<-sq*sp-cv*sq
return(list(sq,sp,cv,x))}
# 2万回の試行データを得る
set.seed(123)
data2<-replicate(20000,xmtr(1000,10000,3000))
# 販売数量データ
squant2<-as.numeric(data2[1,])
# 販売価格データ
sprice2<-as.numeric(data2[2,])
# 単位変動原価データ
costv2<-as.numeric(data2[3,])
# 限界利益データ
margin2<-as.numeric(data2[4,])
# 販売数量の分布
hist(squant2,prob=T,main="販売数量の分布",
breaks = seq(min(squant2), max(squant2), length.out = 31),
xlab="販売数量",ylab="相対頻度",cex.lab=1.2)
describe(squant2,quant=c(0.2,0.4,0.5,0.6,0.8))
# 販売価格の分布
hist(sprice2,prob=F,main="販売価格の分布",
breaks = seq(min(sprice2), max(sprice2), length.out = 31),
xlab="販売価格",ylab="相対頻度",cex.lab=1.2)
describe(sprice2,quant=c(0.25,0.5,0.75))
# 単位変動原価の分布
hist(costv2,prob=T,main="単位変動原価の分布",
breaks = seq(min(costv2), max(costv2), length.out = 31),
xlab="単位変動原価",ylab="相対頻度",cex.lab=1.2)
describe(costv2,quant=c(0.25,0.5,0.75))
# 限界利益の分布
hist(margin2,freq=F,main="限界利益の確率密度",
breaks = seq(min(margin2), max(margin2), length.out = 31),
xlab="限界利益",ylab="確率密度",cex.lab=1.2)
lines(density(margin2),lwd=5,col="cyan")
describe(margin2,quant=c(0.2,0.4,0.5,0.6,0.8))
plot(ecdf(margin2),col="navy",lwd=5,
xlab="限界利益",ylab="分布関数",cex.axis=0.8,
main="限界利益の累積分布",cex.lab=1.2)
grid(40,40,lwd=1,lty=1,col="cyan")
segments(150052,0,150052,0.6,col="red",lwd=3)
segments(-100000,0.6,150052,0.6,col="red",lwd=3)
text(150052,0,"150052",cex=0.6)
text(1000,0.55,"0.6",cex=0.6)
segments(116171,0,116171,0.4,col="red",lwd=3,lty=3)
segments(-100000,0.4,116171,0.4,col="red",lwd=3,lty=3)
text(116171,0,"116171",cex=0.6)
text(1000,0.35,"0.4",cex=0.6)
qq0<-quantile(margin2,probs=c(0.47))
qq0
qq1<-quantile(margin2,probs=c(0.1,0.2,0.3,0.4,
0.5,0.6,0.7,0.8,0.9))
print(round(qq1,digits=0))
(註1)
1970年に当時の錚々(そうそう)たる統計学者や計量経済学者が集まってパネル・ディスカッションが開催された。マクロ計量経済モデルと時系列分析の長所、短所、有効性などについて議論が行われている。表題はパネル・ディスカッション:実証分析の方法--計量経済分析と時系列分析--となってりpdfファイルで4分冊にまとめられている。(下記サイト参照)
現在読んでみても大変に読み応えがあるレポートで要約者も大変な学者と思われる。当時と現在の大きな違いは、いまでは一般人であってもパソコンや統計ソフト、必要なデータがそろえばここで議論されているような話題について自分の茶の間でかなりの程度に体験できる時代になったことだろう。PCの性能向上だけでなく統計処理のソフトウエアも進化し使いやすくなったことを実感する。 https://www.imes.boj.or.jp/
research/papers/japanese/kks6-1.pdf
計量経済分析におけるモンテカルロ法やノンパラメトリック密度の推定については下記参考文献のJohnston Econometric Methods のChapter11でコンパクトに解説されている。
参考文献
James R.Evans,Daid L. Olson(1998) Introduction to Simulation and Risk Analysis, Prentice Hall
(リスク分析・シミュレーション入門 服部正太 監訳(1999)
共立出版株式会社)
Jack Johnston,John DiNardo(1997)
Econometric Methods 4th ed. The McGraw-Hill Companies,Inc.