ARCHの初歩への道
This presents arch(1) model using simple R code examples.options(width=100,warn=-1,digits=5,messages=1)
suppressPackageStartupMessages(library(rugarch)) #for GARCH models
suppressPackageStartupMessages(library(imager))
# ARCH(1)の入門的なモデルの推定についてまとめてみた。
#登山にたとえれば、山岳ガイドが登山口で基本的事項を説明するような
#ものではなく、最寄り駅に降り立った登山客に行きずりの人が登山口は
#あちらの方ですよと話すような内容となっている。
#GARCHのようなボラティリティモデルを推定するにはパッケージ
# rugarchが使いやすい。シミュレーション、推定、予測など様々なモデルを
#このパッケージ一つで処理できる。より詳しい使い方については
#Introduction to the rugarch package (Version 1.3-8) Alexios Ghalanos
#に詳細に書かれている。
#なお、ARMA過程などRを使った時系列分析の基礎を無料で学ぶには
#Rob J Hyndman先生のサイトが分かりやすく、個人的に気に入っている。
#Forecasting: principles and practice という専門書が
# https://otexts.com/fpp2/ で公開されているが、ボラティリティモデル
#は扱われていない。
#ここでは入門書でよく扱われている初歩的なARCH(1)モデルを
#rugarchを使って,分かりやすいようにシミュレーションによるデータを人為的
#に発生させて、その入門的分析を試みる.
# 収益率retの誤差項eが以下の条件に従って時間と共に変動するモデル
#を考える。数式でまとめると以下のようになる。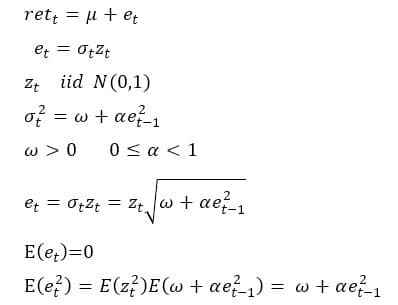
#α=0の場合は分散はωとなり時間の変化にかかわらず一定となる。
# 最初にμ=0.2 ω=1 つまり収益率が0.2で期待値0分散1の
#正規分布をする誤差項を持つ仮想の収益率データを発生させる。
arch1.spec=ugarchspec(variance.model=list(garchOrder=c(1,0)),
mean.model=list(armaOrder=c(0,0)),
fixed.pars=list(mu = 0.2,omega=1,
alpha1=0),
distribution.model="norm")
arch1.sim = ugarchpath(arch1.spec, n.sim=1000,rseed=1)
ret1<-ts(fitted(arch1.sim))
var1<-ts(sigma(arch1.sim))
#シミュレーションで得た仮想の収益率をグラフにすると以下のように
#0.2前後で分布している
plot.ts(ret1)

# 分散をグラフ化すれば以下のように1 で 当然のごとく一定になる。
plot.ts(var1)

# 次にμ=0.2 ω=1 α=0.7 ARCH(1)過程に従って変化する誤
#差項を持つ仮想の収益率データを発生させる。
#garchOrder(q,p)でarch項(q)とgarch項(p)の次数を
#指定する.arch項1個でgarch項なしのARCH(1)モデルを
#作りたいのでgarchOrder=c(1,0)と指定する。
#ちょっとややこしいがarchの次数が1garch項は無いので
#ベクトルでc(1,0)の順番に指定する。
#もしarch(7)としたい場合にはgarchOrder(7,0),もしgarch(1,1)の
#モデルを作りたい時には garchOrder=c(1,1)と指定する。
#mean.modelの中でarmaOrder=c(0,0)と指定しているが、
#平均式ret=μ+e についてARもMAも無いことを示している
#もし平均式retが一次自己回帰モデルとしたい時には
#armaOrder=c(1,0)とする。
#distribution.model="norm"として正規分布を仮定しているが
#必要に応じてt分布"std"や歪んだt分布"sstd"など様々な分布を
#指定できる。ugarchpathの中のrseedは乱数を再現をさせたい
#時に指定する。ここではn.sim=1000として1000個のデータ
#を生成する。
arch11.spec<-ugarchspec(variance.model=list(garchOrder=c(1,0)),
mean.model=list(armaOrder=c(0,0)),
fixed.pars=list(mu = 0.2,omega=1,
alpha1=0.7),
distribution.model="norm" )
arch11.sim <- ugarchpath(arch11.spec, n.sim=1000,rseed=1)
ret2<-ts(fitted(arch11.sim))
var2<-ts(sigma(arch11.sim))
plot.ts(ret2)

plot.ts(var2)

#収益率はある特定の期間に変動のブレ、振幅が大きくなっている。
#また条件付分散は時間と共に変動し、特定の時期に大きな変動が集中する
#ボラティリティクラスタリングが見られる。このような単純なモデルでも
#ボラティリティクラスタリングが観察できることは興味深い。
#上記で発生させた仮想の収益率データ(μ=0.2 ω=1 α=0.7)
# についてrugarchを使って、各パラメーターを推定してみる。
#
#retの条件付分散は直接に観察することは出来ないがARCH過程の仮定の下に、
#観測できる収益率の残差の推定値の2乗を使って最尤法により各パラメータ
#μ、ω、αを推定している。
#仮に単純回帰分析の知識と分析ソフトしか使えない世界にいると仮定すれば
#まずretの平均値を推定し、次にret-平均値=残差を推定し、
#その残差の2乗について,残差2乗(t)=ω+α・残差2乗(t-1)
#について単純回帰で ωやαを推定することになる。しかしARCH過程を前提
#とすれば最尤法により各パラメータμ、ω、αを効率的に推定できる。
#なお、条件付分散を1期前の残差の2乗だけでなくq期前まで遡って拡張した
#条件付分散(t)=ω+α(1)e(t-1)^2+..+α(q)e(t-q)^2 としたモデルを
#ARCH(q)と呼んでいる。
garchSpec2 <- ugarchspec(
variance.model=list(model="sGARCH",garchOrder=c(1,0)),
mean.model=list(armaOrder=c(0,0),include.mean=T,
distribution.model="norm"))
garchFit2 <- ugarchfit(spec=garchSpec2, data=ret2)
#推定結果は以下のようになり、
#ret の期待値 μ=0.20519 条件付分散はω=1.1704 α=0.6493 と推定されて
#おり、条件付分散は 1.17043 +0.64931e(t-1)^2
#と推定されている。ついでに、無条件分散を計算してみると
# ω/(1-α)=1.17043/(1-0.6493)≒3.33 となる。
#実際に何かのデータについて分析する場合は
#事前にARCH過程に従っているかは全く不明なので、ARCH効果の検定や
#モデルの妥当性などの様々な検定と診断をすることになる
#現実的にはこの検定やモデル診断がなかなか難しい作業となる。
show(garchFit2)##
## *---------------------------------*
## * GARCH Model Fit *
## *---------------------------------*
##
## Conditional Variance Dynamics
## -----------------------------------
## GARCH Model : sGARCH(1,0)
## Mean Model : ARFIMA(0,0,0)
## Distribution : norm
##
## Optimal Parameters
## ------------------------------------
## Estimate Std. Error t value Pr(>|t|)
## mu 0.20519 0.037447 5.4794 0
## omega 1.17043 0.085222 13.7339 0
## alpha1 0.64931 0.068516 9.4768 0
##
## Robust Standard Errors:
## Estimate Std. Error t value Pr(>|t|)
## mu 0.20519 0.034425 5.9604 0
## omega 1.17043 0.087952 13.3076 0
## alpha1 0.64931 0.070502 9.2098 0
##
## LogLikelihood : -1823.1
##
## Information Criteria
## ------------------------------------
##
## Akaike 3.6522
## Bayes 3.6670
## Shibata 3.6522
## Hannan-Quinn 3.6578
##
## Weighted Ljung-Box Test on Standardized Residuals
## ------------------------------------
## statistic p-value
## Lag[1] 1.600 0.2060
## Lag[2*(p+q)+(p+q)-1][2] 2.102 0.2464
## Lag[4*(p+q)+(p+q)-1][5] 3.562 0.3140
## d.o.f=0
## H0 : No serial correlation
##
## Weighted Ljung-Box Test on Standardized Squared Residuals
## ------------------------------------
## statistic p-value
## Lag[1] 0.06527 0.7983
## Lag[2*(p+q)+(p+q)-1][2] 0.08520 0.9301
## Lag[4*(p+q)+(p+q)-1][5] 1.14285 0.8266
## d.o.f=1
##
## Weighted ARCH LM Tests
## ------------------------------------
## Statistic Shape Scale P-Value
## ARCH Lag[2] 0.0397 0.500 2.000 0.8421
## ARCH Lag[4] 1.1706 1.397 1.611 0.6553
## ARCH Lag[6] 1.8816 2.222 1.500 0.7068
##
## Nyblom stability test
## ------------------------------------
## Joint Statistic: 0.9106
## Individual Statistics:
## mu 0.1259
## omega 0.3606
## alpha1 0.5732
##
## Asymptotic Critical Values (10% 5% 1%)
## Joint Statistic: 0.846 1.01 1.35
## Individual Statistic: 0.35 0.47 0.75
##
## Sign Bias Test
## ------------------------------------
## t-value prob sig
## Sign Bias 0.1809 0.8565
## Negative Sign Bias 0.7583 0.4484
## Positive Sign Bias 0.1667 0.8676
## Joint Effect 1.3672 0.7132
##
##
## Adjusted Pearson Goodness-of-Fit Test:
## ------------------------------------
## group statistic p-value(g-1)
## 1 20 14.80 0.7352
## 2 30 34.34 0.2270
## 3 40 41.36 0.3680
## 4 50 42.60 0.7287
##
##
## Elapsed time : 0.1761#以下のグラフでもボラティリティクラスタリングをうまくモデル化して
#いるように見える
#残念ながら、モデル診断に関しては Ljing Box test やラグランジュ・テストなど
#の様々なテスト結果も打ち出されているが、なかなかスッキリと帰無仮説を棄却
#できるほどの低いp値が得られておらず、検定の難しさを感じる。
retest <- garchFit2@fit$fitted.values
plot.ts(retest)

varest <- ts(garchFit2@fit$sigma^2)
plot.ts(varest)

#rugarchには予測モデルも作れるので,10期先までの単純な予測を
#試みると#以下のようになる。
fmodel <- ugarchforecast(garchFit2,n.roll=0,n.ahead=10,data=ret2)
plot.ts(fmodel@forecast$seriesFor,ylim=c(-1,1))

plot.ts(fmodel@forecast$sigmaFor,,ylim=c(1,2))

plot(fmodel,which=c(1))

plot(fmodel,which=c(3))

#rolling予測も出来るが、その場合は予測に100個のデータを使うので
#out.sample=100 を指定しておく。rolling forecastについては
#上記の Hyndmanのサイト https://otexts.com/fpp2/ で説明されている。
garchFit3 <- ugarchfit(spec=garchSpec2, data=ret2,out.sample=100)
fmodel2<-ugarchforecast(garchFit3, data = ret2, n.ahead = 10, n.roll
= 10, out.sample = 100)
plot(fmodel2,which="all")
