アルキメデス型のコピュラは生成素という関数Φ()を使って以下のように表現されている。
クレイトンコピュラの生成素(generator)は
その逆関数は
となる。
逆関数の中に生成素の関数を入れると
![]()
と定義し、その逆関数を
![]()
で表している場合がある。理由は分からないが、生成素と逆関数を逆転させて使っている。その場合にはアルキメデス型のコピュラの表記は以下のようにφ(φ-1)の順になる。
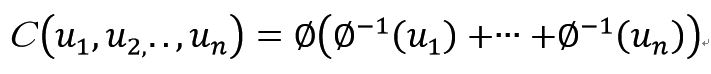
以下では一番最初の方の定義にしたがって生成素を
![]()
その逆関数を
![]()
で表記している。
ここからはMAXIMAを使って生成素とその逆関数の特徴をグラフで見てみる。 0<θ<∞ の範囲に限定する。

生成素をw(t,θ)で表してグラフで示すと
単調減少の凸関数になっている。w(0,θ)=∞
w(1,θ)=0
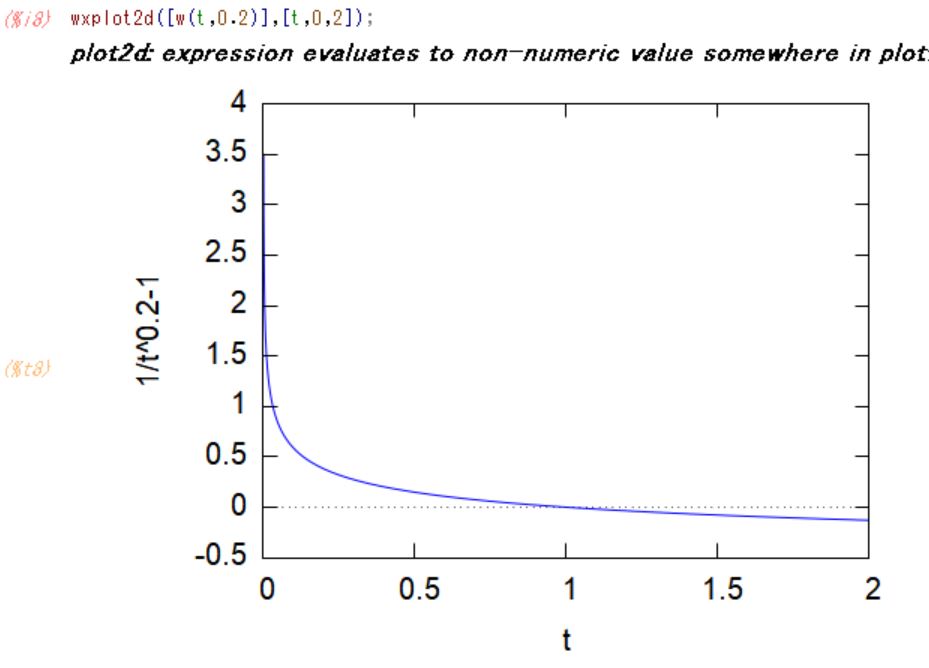
w(t,θ)の逆関数 winv(t,θ)のグラフも見てみると
winv(0,θ)=1,winv(∞,θ)=0
ガンマ分布で形状(shape)パラメータ=1/θ、スケールパラメータ=1とした標準ガンマ分布をラプラス変換するとクレイトンコピュラの生成素の逆関数と同じ数式が選られる。

クレイトンコピュラの乱数を発生させるときにこの関係が使われている。
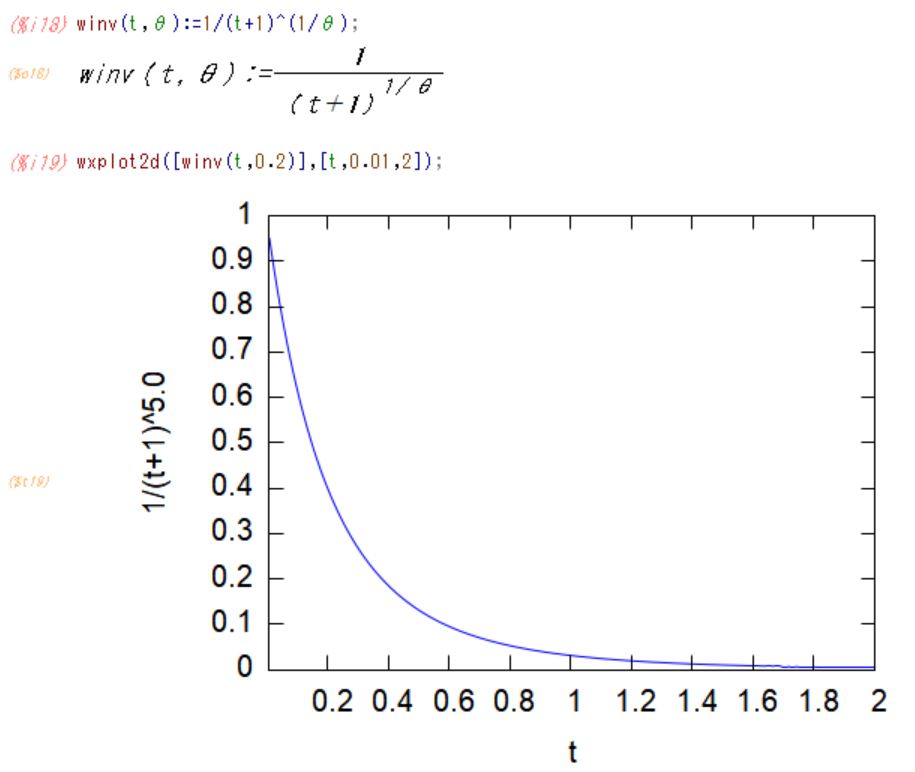
に従って2変数x、yについて、逆関数の中に生成素を代入してクレイトンコピュラを作ると
![]()
と表せる。これは2変数のクレイトンコピュラの同時分布を表している。
同時分布をx、yで偏微分してクレイトンコピュラの密度関数を求めると
![]()
合成関数の微分となるが、念のためにMAXIMAで答合わせをすると
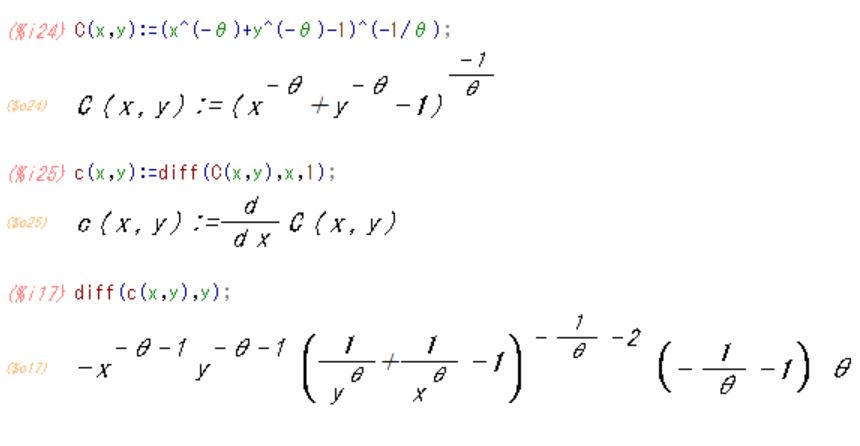
以上でクレイトンコピュラの2変数の同時分布と密度関数が導かれた。
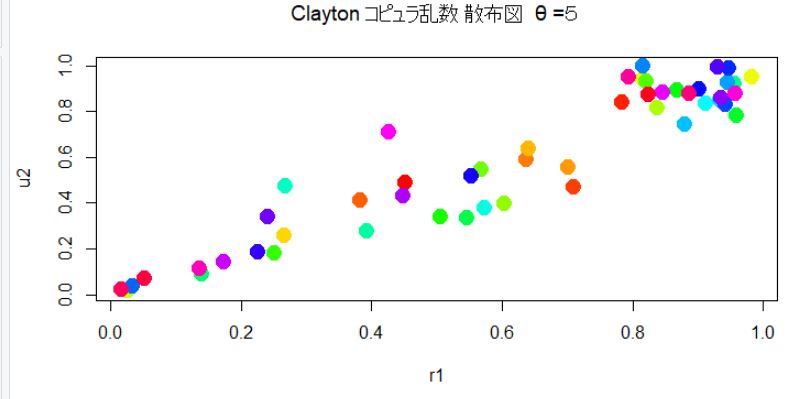
先ほど2変数のクレイトンコピュラの密度関数を求めたので、それを使って密度関数をグラフにすると以下のようになる。左側は等高線を描いている。
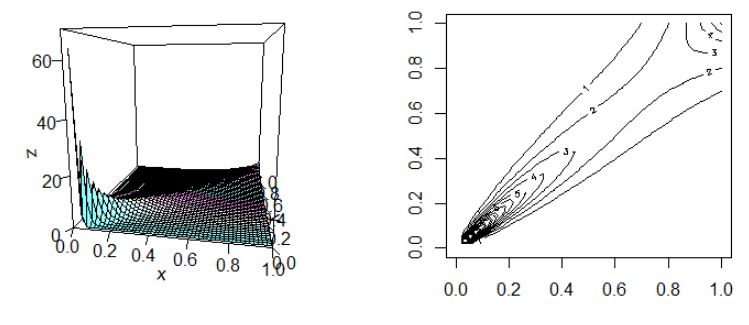
統計ソフトRにはコピュラに係るパッケージが多数あるがライブラリーcopulaを使うと上記の作業は簡単にできる。
最初にθ=5の乱数のペアを50個、生成する。
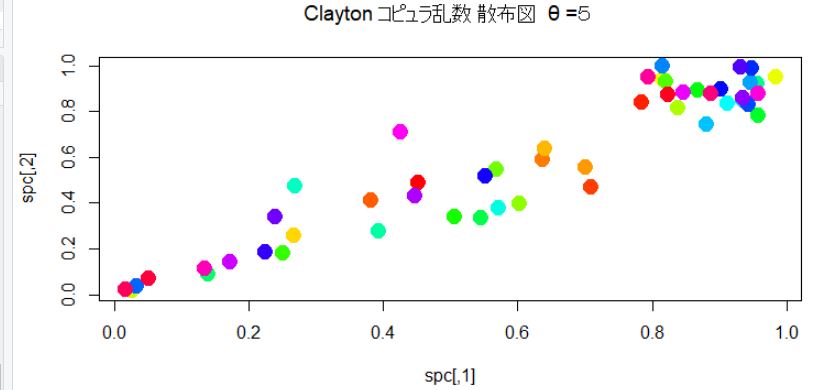
このパッケージを利用して生成した乱数を先ほど作った乱数と比較すると同じよになっている。
r1 u2
[1,] 0.4512674 0.4867697
[2,] 0.7837798 0.8383791
[3,] 0.7096822 0.4675296
[4,] 0.3817443 0.4097074
[5,] 0.6363238 0.5917164
> head(spc)
[,1] [,2]
[1,] 0.4512674 0.4867697
[2,] 0.7837798 0.8383791
[3,] 0.7096822 0.4675296
[4,] 0.3817443 0.4097074
[5,] 0.6363238 0.5917164
多分、パッケージの乱数は先の論文で紹介されていた方法と同じ方法で生成されているのではないかと推測した。
密度関数をグラフにすると
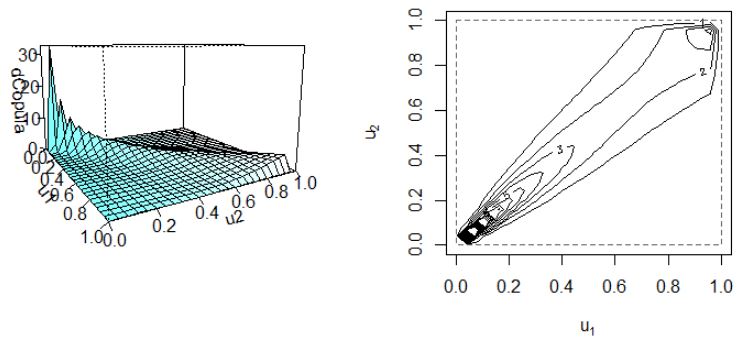
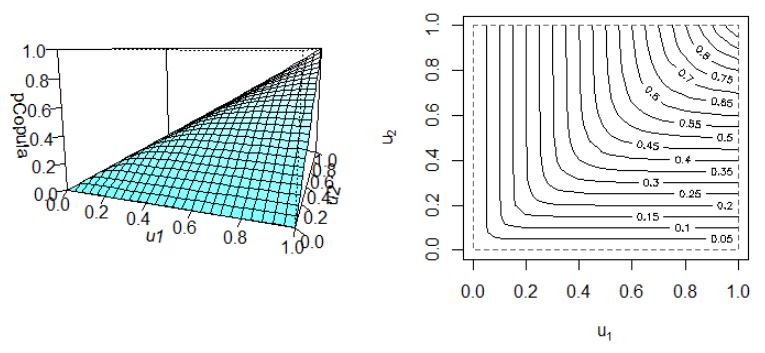
同時分布は以下のようになる。
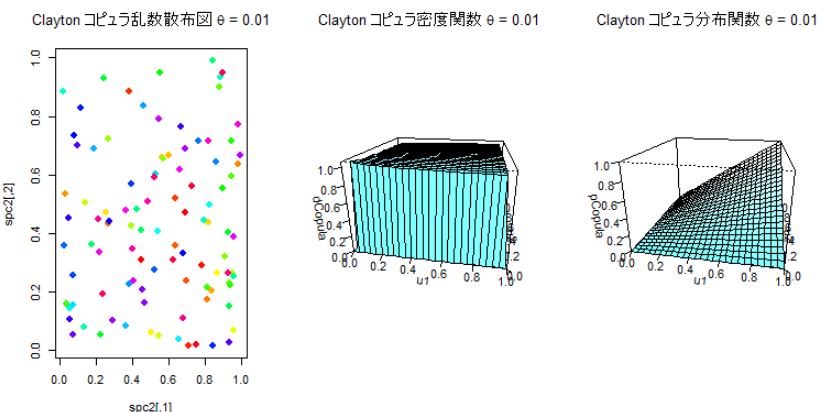
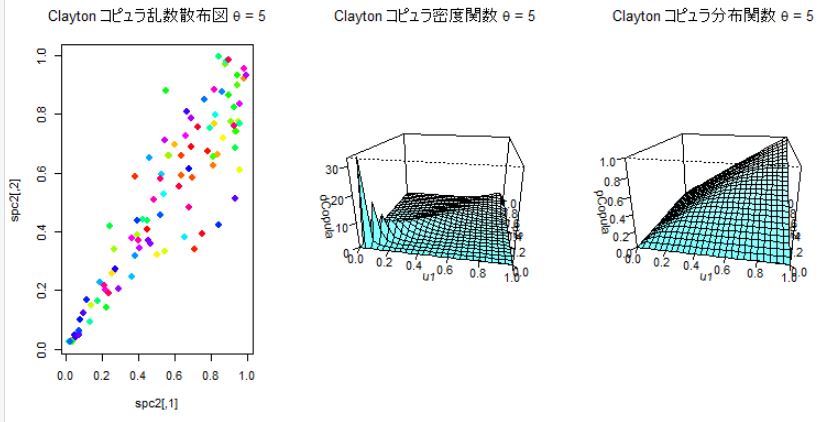
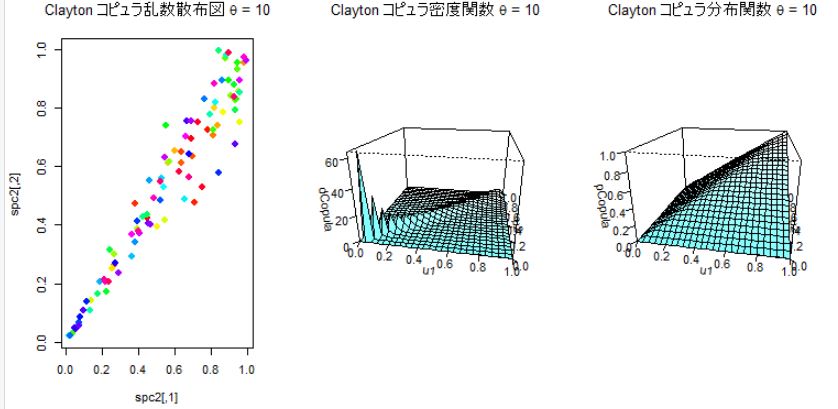
パラメータθをゼロに近い0.01、と5,10の3つのケースについて分布を比べてみる。θが大きくなると依存度が大きくなり∞になると完全依存となる。逆に0に近づくほど依存度は減少していく。θが5の場合は左側(下方部)での依存関係は大きいが右側(上方部)では依存関係は小さくなっている。
θ=0.01のケース
θ=5 のケース
θ=10 のケース
拙文の作成に使ったRコードは以下のとおりである。
library(copula)
set.seed(2021)
theta<-5
r1<-runif(50)
r2<-runif(50)
#####clayton copula 乱数の生成
u2<-(r1^(-theta)*(r2^(-theta/(1+theta))-1)+1)^(-1/theta)
rru2<-cbind(r1,u2)
##コピュラ 散布図
plot(rru2,main=eval(substitute(expression(paste("Clayton コピュラ乱数 散布図 θ =5 ")))),
col=rainbow(50),pch=20,cex=3)
#コピュラ 密度関数
par(mfrow=c(1,2))
x <- seq(0,1,length=50)
y <- x
t <- theta
claydist <- function(x,y,t) {
(1/t+1)*t*(x^(-t-1))*(y^(-t-1))*((1/y^t)+(1/x^t)-1)^(-1/t-2)
}
z <- outer(x,y,claydist,t)
persp(x, y, z, col=cm.colors(1200), tick='detailed',
theta=10, phi=10,zlim=c(0,70))
contour(x,y,z,nlev=50 ,method = "flattest",labcex=0.5)
##コピュラ 分布
cprru2<-(r1^(-theta)+u2^(-theta)-1)^(-1/theta)
cprru2
x <- seq(0,1,length=50)
y <- x
t <- theta
claycumdist <- function(x,y,t) {
(x^(-t)+y^(-t)-1)^(-1/t)}
zz <- outer(x,y,claycumdist,t)
persp(x, y, zz, col=cm.colors(1200), tick='detailed',
theta=10, phi=10)
contour(x,y,zz,nlev=30)
par(mfrow=c(1,1))
##パッケージ copula 利用
theta=5
cx<-claytonCopula(theta,dim=2)
set.seed(2021)
spc<-rCopula(50,cx)
par(mfrow=c(1,1))
##コピュラ 散布図
plot(spc,main=eval(substitute(expression(paste("Clayton コピュラ乱数 散布図 θ =5 ")))),
col=rainbow(50),pch=20,cex=3)
par(mfrow=c(1,2))
persp(claytonCopula(theta),
dCopula,phi=10,theta=60,col=cm.colors(1200))
contour(cx, dCopula,nlev=40)
persp(claytonCopula(theta),
pCopula,phi=10,theta=20,col=cm.colors(1200))
contour(cx, pCopula,nlev=30)
##生成した乱数の比較
head(rru2)
head(spc)
## パッケージ copula で作成された乱数と同じなので多分
#上記の方法と同じ方法を使っているのではないかと推測できる。
par(mfrow=c(1,3))
theta<-c(0.01,5,10)
rannum<-100 #生成する乱数の数
for(i in 1:3){
set.seed(2021)
cxx<-claytonCopula(theta[i],dim=2)
spc2<-rCopula(rannum,cxx)
plot(spc2,main=eval(substitute(expression(paste("Clayton コピュラ乱数散布図 ",theta," =
",j)),
list(j=as.character(theta[i])))),col=rainbow(100),pch=20,cex=2)
persp(cxx,dCopula,main=eval(substitute(expression(paste("Clayton コピュラ密度関数 ",
theta," = ",j)),
list(j=as.character(theta[i])))),col=cm.colors(1200),phi=20,theta=10)
persp(cxx,pCopula,main=eval(substitute(expression(paste("Clayton コピュラ分布関数
",theta," = ",j)),
list(j=as.character(theta[i])))),col=cm.colors(1200),phi=20,theta=10)
}
par(mfrow=c(1,1))